À l’origine de cette note, un post de blog de Baptiste Coulmont sur l’évolution des notes du bac dans le temps. Plus particulièrement, cette courbe représentant la distribution de la moyennes des notes obtenues au baccalauréat entre 2006 et 2013:
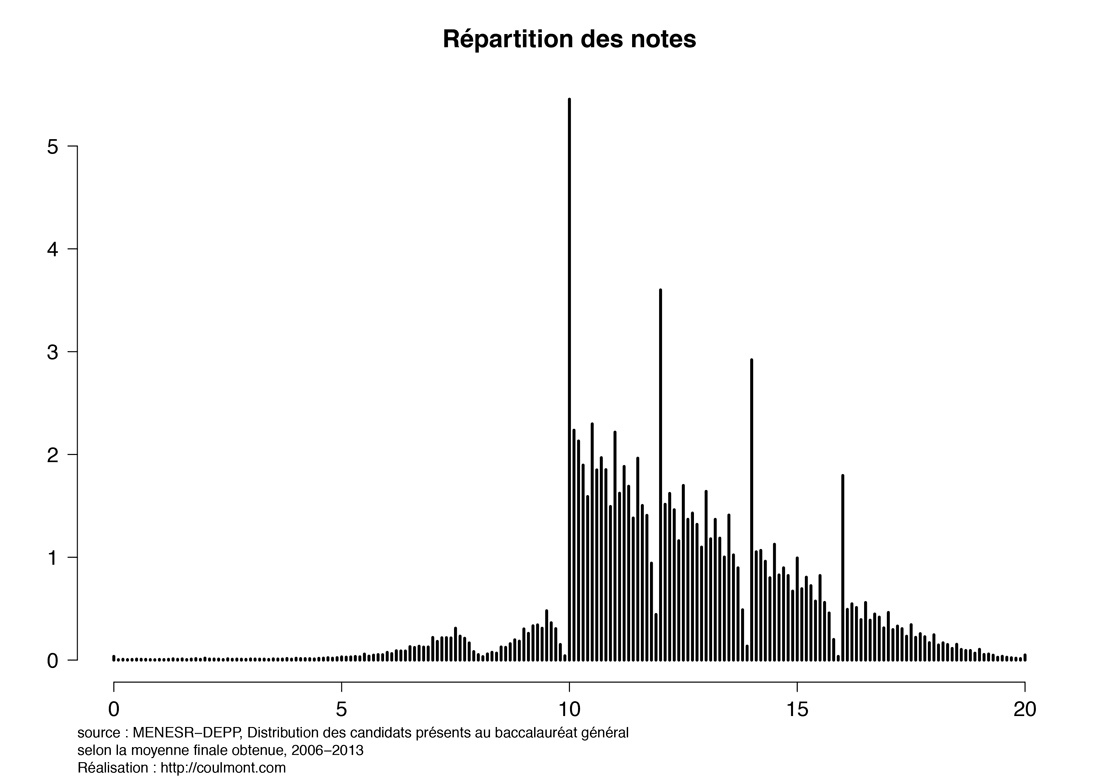
Cette courbe est très éloignée de la gaussienne attendue. Le but de cet exercice de modélisation est de montrer qu’il est néanmoins possible de reproduire cette courbe en supposant que la distribution des moyennes avant l’intervention du jury est normale.
Nous n’avons malheureusement à notre disposition que les données concernant la première session 2016 (si vous avez accès à plus de données, je vous serais reconnaissant de bien vouloir me contacter) :

Cette courbe-ci est aussi éloignée d’une simple loi normale, avec des pics autour des notes 8, 10, 12, 14, 16 qui correspondent respectivement à la note minimale pour aller au rattrapage, la note d’admission, les mentions AB, B et TB. Nous allons montrer ici que la courbe s’explique très bien en supposant que la distribution des moyennes est normale et en modélisant l’intervention du jury.
Modèle
Des notes à l’histogramme
On note la moyenne brute du candidat , c’est-à-dire avant l’intervention du jury :
\begin{equation*}
\theta_n \sim \operatorname{Normal}(\mu, \sigma)
\end{equation*}est la “vraie” moyenne des notes du bac, sa “vraie” déviation standard. Une inspection rapide du graphe nous permet de définir les priors vaguement informatifs suivants:
\begin{align*}
\displaystyle
\mu &\sim \operatorname{Normal}(12,2)\\
\sigma &\sim \max \left[0, \operatorname{Normal}(2.5, 2)\right]
\end{align*}Cependant nous ne disposons par des notes individuelles , mais du vecteur des le nombre de candidats ayant obtenu la note . Pour obtenir ce vecteur les notes sont visiblement arrondies au dixième de point près : nous supposerons qu’une note entre et sera arrondie à 0, entre et à , etc.
Notons le vecteur qui contient le nombre de notes arrondies à , … le nombre de notes arrondies à 20. Nous supposons que ce vecteur est distribué selon une loi multinomiale, où la probabilité de tomber dans la -ème catégorie est donnée par l’intégrale de la distribution des entre et :
\begin{align*}
\mathbf{N} &\sim \operatorname{Multinomial}(\mathbf{p}, N_{candidats})\\
p_{i} &= \int_{0.1\,i-0.05}^{0.1\,i + 0.05} P(\theta_n=\theta|\mu,\sigma) \mathrm{d}\theta
\end{align*}Le modèle est bien moins compliqué que ça en a l’air. On peut l’utiliser pour simuler de fausses données avec le code suivant:
import numpy as np
import scipy.stats as stats
rng = np.random.default_rng()
bins = [0] + [0.05 + 0.1 * i for i in range(200)] + [20]
def simulate(num_candidats, moyenne=12, sd=2.5):
probs = stats.norm(moyenne, sd).cdf(bins)
probs = [b-a for a, b in zip(probs[:-1], probs[1:])]
hist = rng.multinomial(num_candidats, probs)
return hist
Cette simple gaussienne n’est pas une mauvaise approximation à la courbe de départ. Reste maintenant à comprendre d’où viennent les creux et les pics dans les données.
Intervention du jury
On observe un évident effet d’arrondi autour des notes:
- 8 qui détermine si l’élève est admis au rattrapage;
- 10 qui détermine si l’élève est admis;
- 12, 14, 16 qui déterminent les mentions AB, B, TB
On note l’ensemble des notes pour lesquelles on s’attend à observer un effet de seuil et la note du candidat après intervention du jury. On suppose que la probabilité que le jury intervienne, i.e. que décroit de façon exponentielle en fonction de la distance entre et où est l’indice de la note seuil correspondante à la note de l’élève dans :
\begin{align*}
\mathbf{\alpha} &\sim \operatorname{Exponential}(5.)\\
P(\tilde{\theta}_{n} = \omega_{f(n)}) &= \exp \left(-\alpha_{f(n)} (\omega_{f(n)} - \bar{\theta}_{n})\right)
\end{align*}Comme précédemment avec le modèle gaussien il est possible de générer des données synthétiques à partir de ce modèle:
import numpy as np
import scipy.stats as stats
moyennes = notes_df.moyenne.values
rng = np.random.default_rng()
seuils = np.array([8, 10, 12, 14, 16, 1000])
bins = [0] + [0.05 + 0.1 * i for i in range(200)] + [20]
def simulate_all(mu, sd, alpha):
# Les notes sont distribuées selon une gaussienne puis arrondies et regroupées
hist_probs = stats.norm(mu, sd).cdf(bins)
hist_probs = np.array([b-a for a, b in zip(hist_probs[:-1], hist_probs[1:])])
hist = rng.multinomial(np.sum(num_candidats), hist_probs)
# Le jury accorde le rattrapage, l'admission ou la mention
idx = np.searchsorted(seuils, moyennes)
delta = seuils[idx] - moyennes
p_repechage = np.exp(- delta * alpha[idx])
repeches = rng.binomial(hist, p_repechage)
hist -= repeches
for i, seuil in enumerate(seuils):
hist[moyennes == seuil] += np.sum(repeches[idx==i])
return hist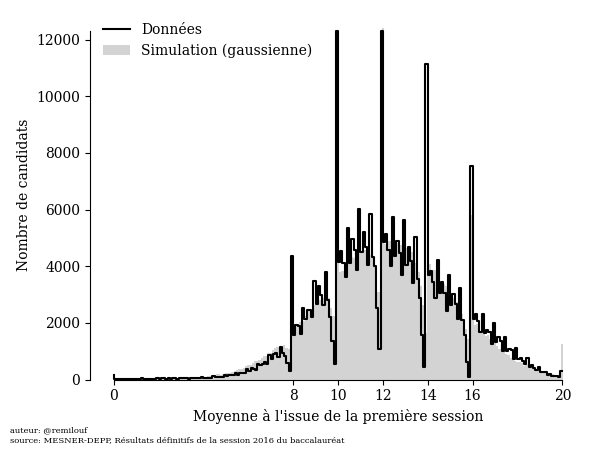
Pas mal!
Inférence
Maintenant que nous avons un modèle capable de produire des données synthétiques proches des donnée observées nous pouvons passer à l’étape suivante: utiliser le modèle avec les données pour calculer la distribution postérieur des paramètres , et . À cause de la nature de l’intervention du jury il est compliqué d’écrire une fonction de vraissemblance pour ce modèle. Nous devons donc utiliser l’Approximate Bayesian Computation. Le modèle s’écrit avec PyMC:
with pm.Model() as model:
mu = pm.Normal("mu", 12, 2)
sd = pm.TruncatedNormal("sd", 2, 1, lower=0.1)
alpha = pm.Exponential("alpha", 5.0, shape=(6,))
s = pm.Simulator(
"s",
simulate_all,
params=(mu, sd, alpha),
epsilon=1000,
observed=num_candidats
)L’inférence se déroule sans problème avec :
with model:
trace = pm.sample_smc(
kernel='ABC',
chains=1,
parallel=True,
save_sim_data=True
)Regardons la trace et la distribution postérieure des différentes variables pour vérifier que tout s’est déroulé sans problème :

Résultats
Avant de se lancer dans des inteprétations vérifions que la distribution postérieure prédictive de notre modèle reproduit les données de façon satisfaisante. Chaque courbe bleue correspond à une simulation :

Le modèle est plutôt bon, mais avec quelques améliorations possibles:
- Le nombre d’élèves repêchés pour la seconde session est surestimé;
- Le nombre d’élève ayant obtenu la note 20 est surestimé. Ceci à cause de l’utilisation de la loi normale pour modéliser la distribution de départ et non une loi définie sur un intervalle comme la loi Beta.
- Les demi-points sont sur-représentés, sûrement un artefact du fait que les copies sont notées à 0.5 point près (à confirmer)
On peut s’amuser à tracer la distribution de la moyenne des notes avant intervention du jury, et la courbe correspondant à l’intervention du jury de sorte à ce qu’en sommant les deux courbes on retrouve les données :

La probabilité que le jury intervienne en faveur d’un candidat n’est clairement pas la même en fonction du seuil qui est concerné:

Plus précisément on peut regarder la probabilité d’intervention lorsque l’on est à un point du seuil. Avec une moyenne de :
- 7 un candidat a 13% de chance d’être au rattrapage;
- 9 un candidat a 7% de chance d’être admis;
- 11 un candidat a 2% de chance d’avoir la mention Bien;
- 13 un candidat a 2% de chance d’avoir la mention Assez Bien;
- 15 un candidat a 6% de chance d’avoir la mention Très Bien;
Au coeur de la controverse de départ, le lieu commun des discussion autour du baccalauréat: on “donne le bac à tout le monde (de nos jours)“. Sans vouloir pour autant tirer de grandes leçon sur l’état de l’Education Nationale et le déclin de la civilisation, nous pouvons estimer le % de candidats qui ont été admis à la seconde session/admis/ont obtenu une mention grâce à l’intervention du jury parmis ceux qui ne l’étaient pas:
| Seuil | % éligibles après intervention du jury |
|---|---|
| Rattrapage | 41% [33%-49%] |
| Admis | 29% [25%-32%] |
| Mention AB | 16% [14%-17%] |
| Mention B | 15% [14%-17%] |
| Mention TB | 15% [13%-17%] |
Le tableau se lit comme suit: “Entre 33% et 49% des candidats qui avaient une moyenne inférieure à 8 ont été admis à la seconde session.” ou “Entre 14% et 17% des élèves qui ont eu une moyenne inférieure à 12 ont eu une une mention AB.”
Maintenant une question légèrement différente: parmis les candidats ayant été admis (ont obtenu une mention), quel % l’a été (l’a obtenue) grâce à l’intervention du jury ?
| Seuil | % obtenu grâce à l’intervention du jury |
|---|---|
| Rattrapage | 13% [10%-15%] |
| Admis | 13% [11%-14%] |
| Mention AB | 14% [12%-15%] |
| Mention B | 18% [16%-19%] |
| Mention TB | 20% [17%-23%] |
Le tableau se lit comme suit: “Entre 17% et 23% des candidats ayant obtenus une mention TB se la sont vu attribuer grâce à l’intervention du jury.”
Conclusion
Pas besoin d’invoquer une version farfelu du théorème de la limite centrale pour justifier la forme de la courbe de départ, elle s’explique en effet très bien par l’intervention du jury sur une distribution qui suit une loi normale. Je suis finalement assez satisfait du modèle (même si quelques petites chose peuvent être améliorées, cf plus haut), et il ne serait pas difficile de le modifier pour modéliser la toute première courbe tirée de l’article de Baptiste Coulmont.
Les principaux enseignements, selon moi est que l’intervention du jury est non-négligeable: 16% des gens ayant eu une mention, ayant été admis sans mention ou ayant été admis à la seconde session le doivent à l’intervention du jury (20% des mentions TB). Nous avons également vu que le jury est plus enclin à “aider” les notes inférieures à 8 : 41% des candidats n’étant a priori pas éligibles à la seconde session l’ont été.
Je suis statisticien, non sociologue, et je laisse donc ces chiffres à qui veut bien les interpréter. Il serait intéressant de faire le même exercice sur les notes finales, et sur plusieurs années: si vous avez les données et souhaitez collaborer ou tout simplement me les envoyer vous pouvez me contacter par mail ou sur twitter.
La suite
Kevin Hédé m’a envoyé un lien vers ces trois jeux de données:
Remarques:
- Les notes avant intervention du jury ne sont pas redressées pour suivre une loi normale; (Kevin Hédé)
- En 2016 points donnés par la modification de la note d’une matière. A partir de 2021: attribution de points du jury (@PVSM
SES)